“Smart” hay “Green” city sẽ là một trong những use case nhận được nhiều sự quan tâm nhất trong thời gian sắp tới. Khái niệm về một thành phố xanh, thông minh không phải là một khái niệm mới được đề cập, nó đã được nhắc đến rất nhiều lần khoảng 5-7 năm gần đây, đặc biệt khi cụm từ chuyển đổi số trở thành một xu hướng tất yếu thì use case này càng trở lên “nóng” hơn bao giờ hết. Trong phạm vi bài viết này, tôi sẽ xử dụng cụm từ “Green City” thay cho “Smart City” vì yếu tố “Green” bao trùm hàm ý “Smart”.
Ta có thể nhận thấy rằng, Green City sẽ là tổng hoà của những thành phần nhỏ hơn trong bức tranh cấu thành nên 1 thành phố. Đó là Green Factory, Green Port, Green Hospital, etc. Mặc dù mỗi thành phần sẽ có những yêu cầu đặc thù riêng vì tính chất của chính nó nhưng tất cả đều cần có một hệ thống thu thập dữ liệu từ đầu vào (producer), xử lý dữ liệu và sử dụng dữ liệu (consumer). Một hệ thống xuyên suốt như vậy ta gọi là một Data PipeLine. Vậy một Data pipeline trong giai đoạn này cần phải đạt được những yếu tố gì? Thiết kế chung của một Data Pipeline có thể được hình dung như thế nào?
Khi áp dụng các công nghệ phục vụ cho chuyển đổi số, các tác vụ sẽ xoay quanh một yếu tố chính: Data. Data trong công cuộc này đa dạng về chủng loại và cả về số lượng, tạo ra một áp lực không hề nhỏ cho các tác vụ xử lý. Các kỹ thuật liên quan đến ETL trong data trước đây vẫn sẽ được sử dụng rộng rãi trong các use cases về batching, tuy nhiên với các realtime data – hay còn gọi là “Data in Motion” thì nhu cầu cần một thiết kế mới về một Data pipeline để làm sao xử lý dữ liệu một cách nhanh nhất và hiệu quả nhất. Các nguồn dữ liệu của “Data in Motion” sẽ đến từ các thiết bị đầu cuối như sensor, camera, etc. được đặt tại các locations gần nhất với end-user để có thể thu thập được dữ liệu realtime. Do đó, ta có thể nhận thấy rằng, các locations này chính là hình thái của Edge Computing khi mà bản thân chúng chính là edge node. Ta sẽ cùng nhau thảo luận về edge location trong các phần trình bày tiếp theo đây vì mỗi vị trí của edge sẽ định hình lên các tác vụ khác nhau mà tại edge cần xử lý, e.g. near edge, far edge. Bên cạnh đó, dữ liệu truyền từ edge locations thông qua các giao thức mạng cần phải được đảm bảo làm sao giảm thiểu tối đa khả năng bị mất dữ liệu vì bất cứ lý do gì xảy ra. Chính vì vậy, giải pháp về một end-to-end pipeline phải đáp ứng được yếu tố fault-tolerance, data consistency, điều này vô cùng quan trọng đối với realtime data streaming.
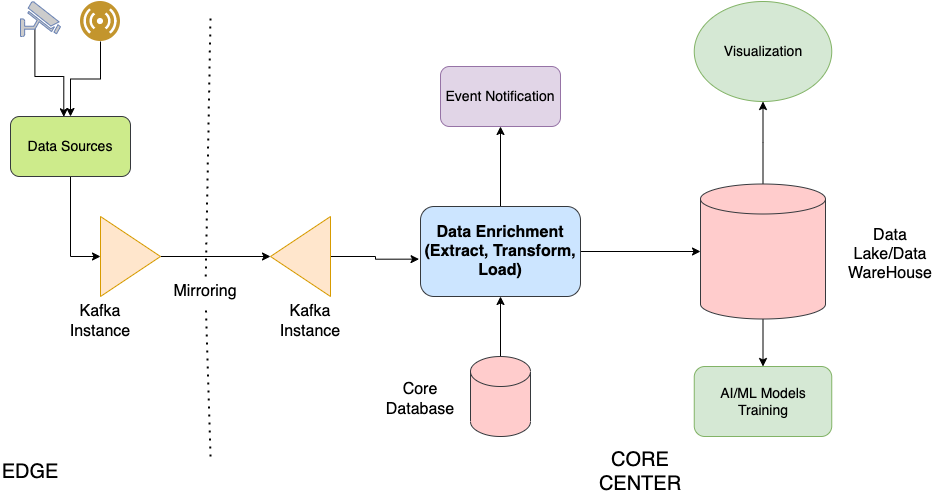
Hãy cùng nhau tham khảo qua về mô hình tổng quan nhất về một thiết kế chung cho Data Pipeline dưới đây:
Tại Edge locations:
- Data được generated từ các nguồn như camera hay sensors trong các use cases của Green City
- Data sẽ được streaming thông qua các giải pháp data streaming, ở đây ví dụ là Kafka.
- Kafka mirroring được ứng dụng để replicate data giữa các kafka clusters. Việc sử dụng Kafka Mirroring cũng giảm thiểu được việc mất dữ liệu trong trường hợp mất kết nối từ Edge tới Core center. Lúc này data sẽ được buffer và lưu tại edge, sau đó sẽ tiếp tục được streaming về core center khi kết nối được khôi phục.
Tại Core center:
- Data nhận được từ Kafka streaming sẽ được “làm giàu” thêm nhờ các data có sẵn từ core center. Quá trình Enrichment a.k.a “làm giàu” dữ liệu sẽ cho ra những thông tin chính xác và đầy đủ hơn bằng cách sử dụng các database tại core center. Dựa trên các thông tin được làm giàu này, tại core center ta có thể triển khai các ứng dụng liên quan đến cảnh bảo (notification).
- Data sau khi được làm giàu sẽ được lưu vào trong data lake/data warehouse nhằm phục vụ cho các tác vụ liên quan đến AI/ML hoặc hiển thị.
[To be continued….]